While performing PITR, would it be possible to Pause/Resume in PostgreSQL ?
Published on Sun, Apr 6, 2014
Yes, truly possible and handled smartly by PostgreSQL. To demo this, first I need to take after the standard technique of Point in Time Recovery in PostgreSQL. Various Books/Articles/Blogs demoed extremely well by extraordinary authors, hence am not going into details of how to do it, however, heading off directly to the subject i.e., how to pause while recovering with same technique. Arguably, I put forth a mathematical expression out of PITR as “PITR = (Last Filesystem Backup(LFB) + WAL Archives generated after LFB + Un-Archived WAL’s in current $PGDATA/pg_xlogs)”. For better understanding, I have put this into graph, in light of the fact that it clear the thought more: (Sorry, this blog is bit long, unknowingly it happened while going in details of the concept)
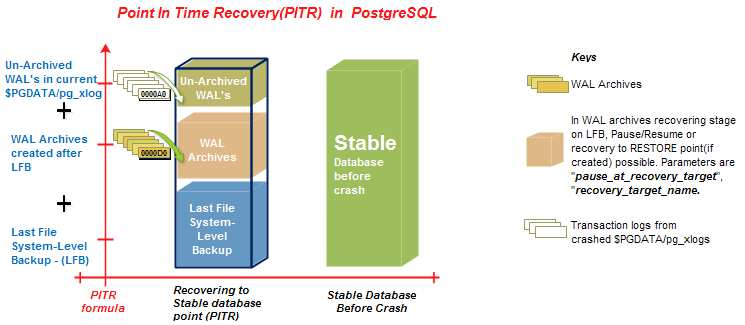
PITR steps,which am going to follow with slight changes that I talk about soon:
Step 1. Restore the most recent File
System-level backup(FSB) to any location where recovery is planned to
perform.
Step 2. If FSB is tar,then untar it, and
clean the pg_xlog directory leaving archive_status. If backup has
excluded this directory, then create the empty pg_xlog directory in
FSB.
Step 3. Copy un-archived WAL’s from crashed
cluster $PGDATA/pg_xlog into $FSB/pg_xlog (Step 2)
Step 4. Delete the postmaster.pid from FSB
directory.
Step 5. Create recovery.conf file in FSB
directory.
*Step 6. Start the cluster (FSB). *
We should put question, when pausing the recovery required ?. Maybe, to prevent multiple base restorations or roll-forward recovery but check in between or rollback a particular tables data or interest to see how far it has recovered :). Remember, pause in recovery means, its allowing to connect while recovering. To outline this, I have reproduced a situation in chart of a particular table rows improvement until to a mishap.
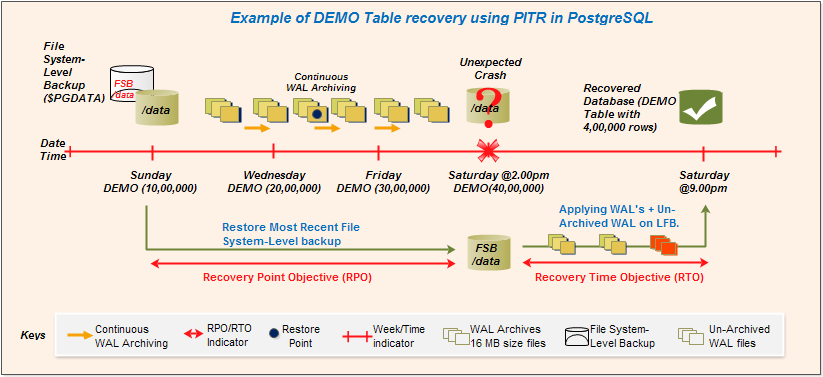
From above diagram, its agreeable a DEMO table rows were 10,00,000 when file system-level backup($PGDATA) taken and 40,00,000 rows before crash. In my local VM, I have made the situation on groundwork of TIME instead of date.
Pre-Requisite:
- File System-Level Backup when DEMO tables having 10,00,000 rows.
- From that point forward, WAL Archives before crash where DEMO table having 40,00,000 rows.
- WAL Archives Location: /opt/PostgreSQL/9.3/archives.
- Data Directory : /opt/PostgreSQL/9.3/data (PGDATA)
- Backup Location : /opt/PostgreSQL/9.3/backups
Keep in mind, working with pause recovery need compulsory changes on main cluster($PGDATA) “wal_level” set to “hot_standby” and on recovery cluster(file system-level backup) “hot_standby” set to “ON”. I have made these changes to main cluster, restarted the cluster to take effect and initiated the backup. If you don’t mind make a note it simply a demo, so my WAL archives might not be gigantic number’s as they are in few numbers. I have listed WAL archives too here, which were generated from the time of backup to crash.
-bash-4.1$ psql -c "select count(*), now() from demo;"
count | now
---------+-------------------------------
1000000 | 2014-04-04 15:06:04.036928-07
(1 row)
-bash-4.1$ pg_basebackup -D /opt/PostgreSQL/9.3/backup/data_pitr -- I have my $PGDATA, $PGUSER, $PGPORT set, so its a straight command in my case
NOTICE: pg_stop_backup complete, all required WAL segments have been archived
Current state of WAL archives and $PGDATA/pg_xlog
-bash-4.1$ ls -lrth /opt/PostgreSQL/9.3/archives
-rw------- 1 postgres postgres 16M Apr 4 16:01 00000001000000000000001C
-rw------- 1 postgres postgres 16M Apr 4 16:01 00000001000000000000001D
-rw------- 1 postgres postgres 289 Apr 4 16:06 00000001000000000000001E.000000C8.backup
-rw------- 1 postgres postgres 16M Apr 4 16:06 00000001000000000000001E
-bash-4.1$ ls -lrth /opt/PostgreSQL/9.3/data/pg_xlog | tail -4
-rw------- 1 postgres postgres 289 Apr 4 16:06 00000001000000000000001E.000000C8.backup
-rw------- 1 postgres postgres 16M Apr 4 16:06 00000001000000000000001E
-rw------- 1 postgres postgres 16M Apr 4 16:06 00000001000000000000001F
drwx------ 2 postgres postgres 4.0K Apr 4 16:13 archive_status
Fine now, we have the backup copy, lets INSERT few records in three parts by noting the time, so it will help to pause recovery and additionally see the WAL’s produced from the time of FSB.
-bash-4.1$ psql -c "insert into demo values (generate_series(1,1000000));"
INSERT 0 1000000
-bash-4.1$ psql -c "select count(*),now() from demo;"
count | now
---------+-------------------------------
2000000 | 2014-04-04 16:06:34.941615-07
(1 row)
-bash-4.1$ psql -c "insert into demo values (generate_series(1,1000000));"
INSERT 0 1000000
-bash-4.1$ psql -c "select count(*),now() from demo;"
count | now
---------+-------------------------------
3000000 | 2014-04-04 16:10:31.136725-07
(1 row)
-bash-4.1$ psql -c "insert into demo values (generate_series(1,1000000));"
INSERT 0 1000000
-bash-4.1$ psql -c "select count(*),now() from demo;"
count | now
---------+-------------------------------
4000000 | 2014-04-04 16:13:00.136725-07
(1 row)
Check the number of WAL’s produced during the INSERT.
-bash-4.1$ ls -lrth /opt/PostgreSQL/9.3/archives
-rw------- 1 postgres postgres 289 Apr 4 16:06 00000001000000000000001E.000000C8.backup
-rw------- 1 postgres postgres 16M Apr 4 16:06 00000001000000000000001E
-rw------- 1 postgres postgres 16M Apr 4 16:06 00000001000000000000001F
-rw------- 1 postgres postgres 16M Apr 4 16:06 000000010000000000000020
-rw------- 1 postgres postgres 16M Apr 4 16:06 000000010000000000000021
-rw------- 1 postgres postgres 16M Apr 4 16:06 000000010000000000000022
-rw------- 1 postgres postgres 16M Apr 4 16:06 000000010000000000000023
-rw------- 1 postgres postgres 16M Apr 4 16:06 000000010000000000000024
-rw------- 1 postgres postgres 16M Apr 4 16:06 000000010000000000000025
-rw------- 1 postgres postgres 16M Apr 4 16:06 000000010000000000000026
-rw------- 1 postgres postgres 16M Apr 4 16:10 000000010000000000000027
-rw------- 1 postgres postgres 16M Apr 4 16:10 000000010000000000000028
-rw------- 1 postgres postgres 16M Apr 4 16:10 000000010000000000000029
-rw------- 1 postgres postgres 16M Apr 4 16:10 00000001000000000000002A
-rw------- 1 postgres postgres 16M Apr 4 16:13 00000001000000000000002B
Assume at this point mishap happened and you have to do recovery using FSB + WAL archives + Unarchived WAL’s(if any). During recovery, I want to pause three time to see each recovery of 20,00,000, 30,00,000 and 40,00,000 rows of DEMO table by connecting to the database in READ-ONLY mode. For each resume of recovery need a restart of recovery cluster by bumping to new timeline in recovery.conf/recovery_target_time. Also,in $FSB/postgresql.conf, we have to set hot_standby=on. Here’s my recovery.conf file:
-bash-4.1$ more recovery.conf
pause_at_recovery_target = true
#recovery_target_time = '2014-04-04 16:06:34' # For 2 lakh records
#recovery_target_time = '2014-04-04 16:10:31' # For 3 lakh records
#recovery_target_time = '2014-04-04 16:13:00' # For 4 lakh records
restore_command = 'cp /opt/PostgreSQL/9.3/archives/%f %p'
Let’s start recovery for 20,00,000 records:
-bash-4.1$ /opt/PostgreSQL/9.3/bin/pg_ctl -D /opt/PostgreSQL/9.3/data_pitr/ start
server starting
Now in logs:
-bash-4.1$ more postgresql-2014-04-04_162524.log
2014-04-04 16:25:24 PDT-24187---[] LOG: starting point-in-time recovery to 2014-02-06 18:48:56-08
2014-04-04 16:25:24 PDT-24187---[] LOG: restored log file "00000001000000000000001E" from archive
2014-04-04 16:25:24 PDT-24187---[] LOG: redo starts at 0/1E0000C8
2014-04-04 16:25:24 PDT-24187---[] LOG: consistent recovery state reached at 0/1E000190
2014-04-04 16:25:24 PDT-24185---[] LOG: database system is ready to accept read only connections
2014-04-04 16:25:24 PDT-24187---[] LOG: restored log file "00000001000000000000001F" from archive
2014-04-04 16:25:24 PDT-24187---[] LOG: restored log file "000000010000000000000020" from archive
2014-04-04 16:25:25 PDT-24187---[] LOG: restored log file "000000010000000000000021" from archive
2014-04-04 16:25:25 PDT-24187---[] LOG: restored log file "000000010000000000000022" from archive
2014-04-04 16:25:25 PDT-24187---[] LOG: recovery stopping before commit of transaction 1833, time 2014-04-04 16:06:23.893487-07
2014-04-04 16:25:25 PDT-24187---[] LOG: recovery has paused
2014-04-04 16:25:25 PDT-24187---[] HINT: Execute pg_xlog_replay_resume() to continue
Cool, see in logs it has paused and a smart HINT asking to resume. Here, if the recovery was satisfactory, you can resume it by calling “select pg_xlog_replay_resume();"(You can check it out). Lets not resume now, however check the number of rows recovered by connecting to the server.
-bash-4.1$ psql -c "select count(*),pg_is_in_recovery() from demo;"
count | pg_is_in_recovery
---------+-------------------
2000000 | t
(1 row)
Good, it has reached to the point and paused where I requested. Lets move one more step ahead for recovering 30,00,000 rows. Now, set the next timeline in recovery.conf/recovery_target_time and restart the cluster.
2014-04-04 16:28:40 PDT-24409---[] LOG: restored log file "00000001000000000000002A" from archive
2014-04-04 16:28:40 PDT-24409---[] LOG: recovery stopping before commit of transaction 1836, time 2014-04-04 16:10:40.141175-07
2014-04-04 16:28:40 PDT-24409---[] LOG: recovery has paused
2014-04-04 16:28:40 PDT-24409---[] HINT: Execute pg_xlog_replay_resume() to continue.
-bash-4.1$ psql -c "select count(*),pg_is_in_recovery() from demo;"
count | pg_is_in_recovery
---------+-------------------
3000000 | t
(1 row)
Nice…, let’s give the last attempt to pause at 40,00,000 rows.
2014-04-04 20:09:07 PDT-4723---[] LOG: restored log file "00000001000000000000002B" from archive
cp: cannot stat `/opt/PostgreSQL/9.3/archives/00000001000000000000002C': No such file or directory
2014-04-04 20:09:07 PDT-4723---[] LOG: redo done at 0/2B0059A0
2014-04-04 20:09:07 PDT-4723---[] LOG: last completed transaction was at log time 2014-04-04 16:11:12.264512-07
2014-04-04 20:09:07 PDT-4723---[] LOG: restored log file "00000001000000000000002B" from archive
2014-04-04 20:09:07 PDT-4723---[] LOG: restored log file "00000002.history" from archive
2014-04-04 20:09:07 PDT-4723---[] LOG: restored log file "00000003.history" from archive
2014-04-04 20:09:07 PDT-4723---[] LOG: restored log file "00000004.history" from archive
cp: cannot stat `/opt/PostgreSQL/9.3/archives/00000005.history': No such file or directory
2014-04-04 20:09:07 PDT-4723---[] LOG: selected new timeline ID: 5
cp: cannot stat `/opt/PostgreSQL/9.3/archives/00000001.history': No such file or directory
2014-04-04 20:09:07 PDT-4723---[] LOG: archive recovery complete
2014-04-04 20:09:08 PDT-4721---[] LOG: database system is ready to accept connections
2014-04-04 20:09:08 PDT-4764---[] LOG: autovacuum launcher started
-bash-4.1$ psql -c "select count(*),pg_is_in_recovery() from demo;"
count | pg_is_in_recovery
---------+-------------------
4000000 | f
(1 row)
Oops, what happened, why it has not paused and what its complaining?. Keep in mind, if no WAL archives present at the time of recovery_target_time then it won’t pause and expect as it has arrived to the last point and open the database for READ/WRITE. In logs, without much stretch make out it was hunting down for file “00000001000000000000002C” which’s not available, because at that time cluster has crashed. Some may not acknowledge this behaviour but its fact and makes sense when no WAL archives present then there’s no reason for pausing the recovery. If at all required to pause even after no WAL archives, then make use of standby_mode=‘on’ (HOT_STANDBY), in this method it won’t come out of recovery but wait for WAL Archives.
Hope it was useful.
–Raghav