Implementing Switchover/Switchback in PostgreSQL 9.3.
Published on Mon, Dec 29, 2014
This post educates sophisticated DBA’s on how to setup graceful Switchover and Switchback environment in PostgreSQL high availability. Firstly, thanks to patch authors Heikkiand Fujii for making Switchover/Switchback easier in PostgreSQL 9.3.(Pardom me if I missed other names).
Let me attempt to illustrate it in short prior to these patches, all of you know Standby’s are critical components in achieving fast and safe disaster recovery. In PostgreSQL, recovery concept majorly deals with timelines to identify a series of WAL segments before and after the PITR or promotion of Standby to avoid overlapping of WAL segments. Timeline ID are associated with WAL segment file names(Eg:- In $PGDATA/pg_xlog/0000000C000000020000009E segment “0000000C” is timeline ID). In Streaming Replication both Primary and Slave will follow the same timeline ID, however when Standby gets promotion as new master by Switchover it bumps the timeline ID and old Primary refuses to restart as Standby due to timeline ID difference and throw error message as:
FATAL: requested timeline 10 is not a child of this server's history
DETAIL: Latest checkpoint is at 2/9A000028 on timeline 9, but in the history of the requested timeline, the server forked off from that timeline at 2/99017E68.
Thus, a new Standby has to be built from scratch, if the database size is huge then a longer time to rebuild and for this period newly promoted Primary will be running without Standby. There’s also other issue like, when Switchover happens Primary does clean shutdown, Walsender process sends all outstanding WAL records to the standby but it doesn’t wait for them to be replicated before it exits. Walreceiver fails to apply those outstanding WAL records as it detects closure of connection and exits.
Today, with two key software updates in PostgreSQL 9.3, both of the issues addressed very well by authors and now Streaming Replication Standby’s follow a timeline switch consistently. We can now seamlessly and painlessly switch the duties between Primary and Standby by just restarting and majorly reducing rebuild time of Standby.
Note: Switchover/Switchback not possible if WAL Archives are not accessible to both servers and in Switchover process Primary database must do clean shutdown(normal or fast mode).
To demo, lets start with setup of Streaming Replication(wiki to setup SR) which I have configured in my local VM between two clusters (5432 as Primary and 5433 as Standby) sharing a common WAL archives location, because both clusters should have complete access of sequence of WAL archives. Look at the snapshot shared below with setup details and current timeline ID for better understanding of concept.
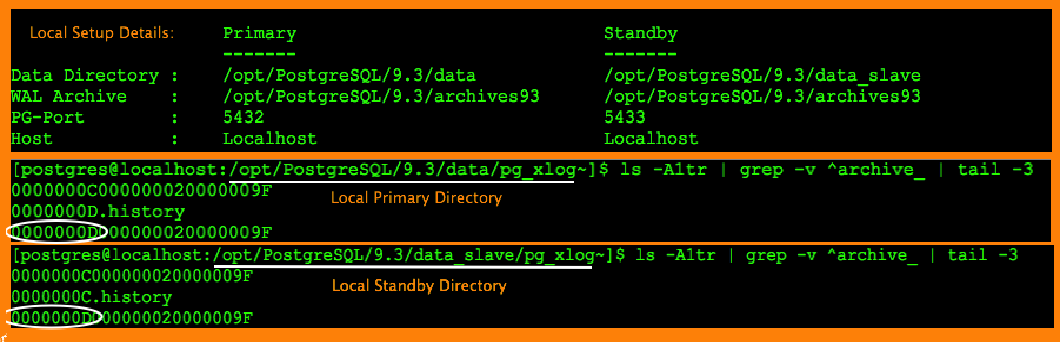
At this stage everyone must have a solid understanding that Switchover and Switchback are planned activities. Now SR setup in place we can exchange the duties of primary and standby as shown below:
Switchover steps:
Step 1. Do clean shutdown of Primary[5432] (-m fast or smart)
[postgres@localhost:/~]$ /opt/PostgreSQL/9.3/bin/pg_ctl -D /opt/PostgreSQL/9.3/data stop -mf
waiting for server to shut down.... done
server stopped
**Step 2. **Check for sync status and recovery status of Standby[5433] before promoting it:
[postgres@localhost:/opt/PostgreSQL/9.3~]$ psql -p 5433 -c 'select pg_last_xlog_receive_location() "receive_location",
pg_last_xlog_replay_location() "replay_location",
pg_is_in_recovery() "recovery_status";'
receive_location | replay_location | recovery_status
------------------+-----------------+-----------------
2/9F000A20 | 2/9F000A20 | t
(1 row)
Standby in complete sync. At this stage we are safe to promote it as
Primary.
**Step 3. **Open the Standby as new
Primary by pg_ctl promote or creating a trigger file.
[postgres@localhost:/opt/PostgreSQL/9.3~]$ grep trigger_file data_slave/recovery.conf
trigger_file = '/tmp/primary_down.txt'
[postgres@localhost:/opt/PostgreSQL/9.3~]$ touch /tmp/primary_down.txt
[postgres@localhost:/opt/PostgreSQL/9.3~]$ psql -p 5433 -c "select pg_is_in_recovery();"
pg_is_in_recovery
-------------------
f
(1 row)
In Logs:
2014-12-29 00:16:04 PST-26344-- [host=] LOG: trigger file found: /tmp/primary_down.txt
2014-12-29 00:16:04 PST-26344-- [host=] LOG: redo done at 2/A0000028
2014-12-29 00:16:04 PST-26344-- [host=] LOG: selected new timeline ID: 14
2014-12-29 00:16:04 PST-26344-- [host=] LOG: restored log file "0000000D.history" from archive
2014-12-29 00:16:04 PST-26344-- [host=] LOG: archive recovery complete
2014-12-29 00:16:04 PST-26342-- [host=] LOG: database system is ready to accept connections
2014-12-29 00:16:04 PST-31874-- [host=] LOG: autovacuum launcher started
Standby has been promoted as master and a new timeline followed which
you can notice in logs.
Step 4. Restart old Primary as
standby and allow to follow the new timeline by passing
“recovery_target_timline=‘latest’” in $PGDATA/recovery.conf file.
[postgres@localhost:/opt/PostgreSQL/9.3~]$ cat data/recovery.conf
recovery_target_timeline = 'latest'
standby_mode = on
primary_conninfo = 'host=localhost port=5433 user=postgres'
restore_command = 'cp /opt/PostgreSQL/9.3/archives93/%f %p'
trigger_file = '/tmp/primary_131_down.txt'
[postgres@localhost:/opt/PostgreSQL/9.3~]$ /opt/PostgreSQL/9.3/bin/pg_ctl -D /opt/PostgreSQL/9.3/data start
server starting
If you go through recovery.conf its very clear that old Primary trying to connect to 5433 port as new Standby pointing to common WAL Archives location and started.
In Logs:
2014-12-29 00:21:17 PST-32315-- [host=] LOG: database system was shut down at 2014-12-29 00:12:23 PST
2014-12-29 00:21:17 PST-32315-- [host=] LOG: restored log file "0000000E.history" from archive
2014-12-29 00:21:17 PST-32315-- [host=] LOG: entering standby mode
2014-12-29 00:21:17 PST-32315-- [host=] LOG: restored log file "0000000D00000002000000A0" from archive
2014-12-29 00:21:17 PST-32315-- [host=] LOG: restored log file "0000000D.history" from archive
2014-12-29 00:21:17 PST-32315-- [host=] LOG: consistent recovery state reached at 2/A0000090
2014-12-29 00:21:17 PST-32315-- [host=] LOG: record with zero length at 2/A0000090
2014-12-29 00:21:17 PST-32310-- [host=] LOG: database system is ready to accept read only connections
2014-12-29 00:21:17 PST-32325-- [host=] LOG: started streaming WAL from primary at 2/A0000000 on timeline 14
Step 5. Verify the new Standby status.
[postgres@localhost:/opt/PostgreSQL/9.3~]$ psql -p 5432 -c "select pg_is_in_recovery();"
pg_is_in_recovery
-------------------
t
(1 row)
Cool, without any re-setup we have brought back old Primary as new Standby.
Switchback steps:
Step 1. Do clean shutdown of new Primary [5433]:
[postgres@localhost:/opt/~]$ /opt/PostgreSQL/9.3/bin/pg_ctl -D /opt/PostgreSQL/9.3/data_slave stop -mf
waiting for server to shut down.... done
server stopped
Step 2. Check for sync status of
new Standby [5432] before promoting.
**Step 3. **Open the new Standby
[5432] as Primary by creating trigger file or pg_ctl promote.
[postgres@localhost:/opt/PostgreSQL/9.3~]$ touch /tmp/primary_131_down.txt
Step 4. Restart stopped new Primary [5433] as new Standby.
[postgres@localhost:/opt/PostgreSQL/9.3~]$ more data_slave/recovery.conf
recovery_target_timeline = 'latest'
standby_mode = on
primary_conninfo = 'host=localhost port=5432 user=postgres'
restore_command = 'cp /opt/PostgreSQL/9.3/archives93/%f %p'
trigger_file = '/tmp/primary_down.txt'
[postgres@localhost:/opt/PostgreSQL/9.3~]$ /opt/PostgreSQL/9.3/bin/pg_ctl -D /opt/PostgreSQL/9.3/data_slave start
server starting
You can verify the logs of new Standby.
In logs:
[postgres@localhost:/opt/PostgreSQL/9.3/data_slave/pg_log~]$ more postgresql-2014-12-29_003655.log
2014-12-29 00:36:55 PST-919-- [host=] LOG: database system was shut down at 2014-12-29 00:34:01 PST
2014-12-29 00:36:55 PST-919-- [host=] LOG: restored log file "0000000F.history" from archive
2014-12-29 00:36:55 PST-919-- [host=] LOG: entering standby mode
2014-12-29 00:36:55 PST-919-- [host=] LOG: restored log file "0000000F.history" from archive
2014-12-29 00:36:55 PST-919-- [host=] LOG: restored log file "0000000E00000002000000A1" from archive
2014-12-29 00:36:55 PST-919-- [host=] LOG: restored log file "0000000E.history" from archive
2014-12-29 00:36:55 PST-919-- [host=] LOG: consistent recovery state reached at 2/A1000090
2014-12-29 00:36:55 PST-919-- [host=] LOG: record with zero length at 2/A1000090
2014-12-29 00:36:55 PST-914-- [host=] LOG: database system is ready to accept read only connections
2014-12-29 00:36:55 PST-929-- [host=] LOG: started streaming WAL from primary at 2/A1000000 on timeline 15
2014-12-29 00:36:56 PST-919-- [host=] LOG: redo starts at 2/A1000090
Very nice, without much time we have switched the duties of Primary and Standby servers. You can even notice the increment of the timeline IDs from logs for each promotion.
Like others all my posts are part of knowledge sharing, any comments or corrections are most welcome. :)
–Raghav